
Security misconfiguration is a security weakness caused by unsafe settings in systems that otherwise work as designed. Nothing is broken in the usual sense. The problem is that a control exists but is not enforced, a feature is exposed that should be private, or a default is left in place long after deployment.
This risk keeps rising because modern cyber and cybersecurity environments are built from highly configurable services. The more knobs a platform offers, the easier it becomes to ship something that functions and still leaves a gap. Misconfiguration is rarely one dramatic mistake. It is more often a chain of small decisions that quietly expands access, reduces visibility, or widens blast radius.
In the OWASP Top 10 for 2025, Security Misconfiguration remains a major category. OWASP reports that all applications in the dataset showed some form of misconfiguration, with an average incidence rate of 3.00 percent and more than 719,000 occurrences mapped to this risk category. Those numbers matter because they describe scale, not edge cases.
What Counts as a Security Misconfiguration
A security misconfiguration is any setting that creates a path an attacker can use or a defender cannot reliably see. It shows up across layers.
It can be a public management interface, an overly broad identity role, a storage service that allows public reads, logging that is disabled, encryption that is inconsistently enforced, or a template that drifts after manual edits. Misconfiguration also applies to security tools. A detection platform that is deployed but not receiving audit logs is misconfigured in a way that directly increases risk.
A practical definition that works in real teams is simple. If the system is more reachable, more permissive, or less observable than you intended, you have a misconfiguration.
How Security Misconfiguration Leads to a Breach
Misconfigurations do not usually cause immediate failure, so they survive change after change. Then an external trigger arrives. A credential is phished, an access key leaks into a repository, an intern tests an endpoint from a coffee shop network, or a rushed production change opens a port for troubleshooting and never closes it.
From an attacker perspective, misconfiguration is attractive because it often removes the need for sophisticated exploitation. A software vulnerability might require an exploit chain. A misconfiguration can provide legitimate access that was never meant to exist.
The impact grows when misconfiguration combines with permissions design. Weak boundaries turn a small foothold into broad reach. Poor segmentation turns one compromised workstation into lateral movement. Missing audit logs turn a detectable incident into a mystery that drags on for weeks.
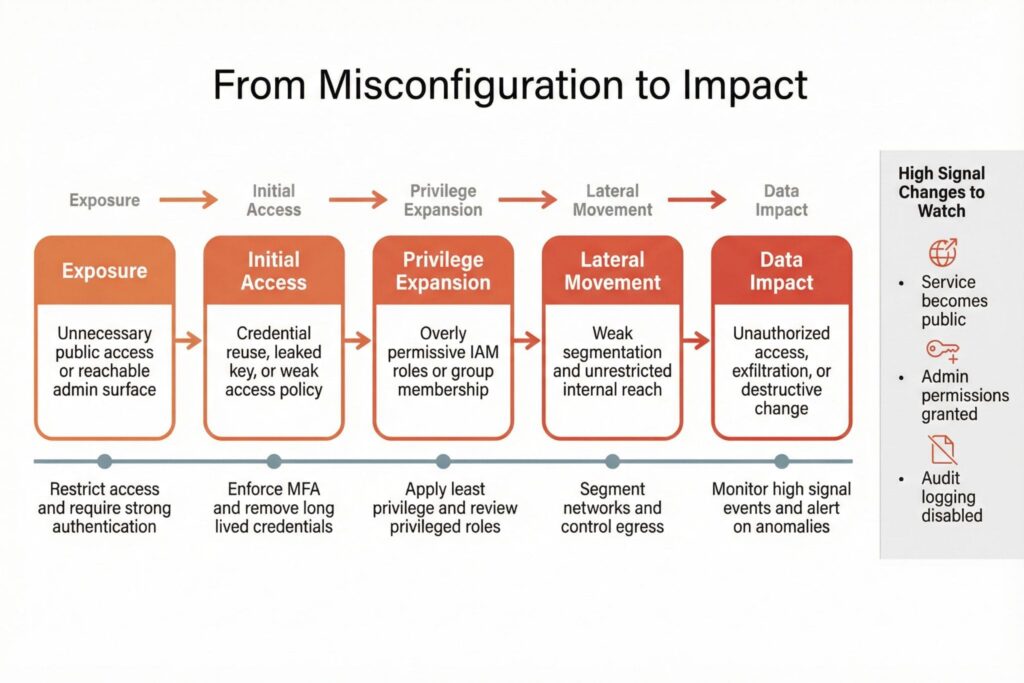
Consider the 2019 Capital One breach as a definitive example. It did not rely on a novel zero-day exploit. Instead, a misconfigured Web Application Firewall (WAF) allowed an attacker to query the metadata service. Critically, the WAF was assigned an overly broad identity role that had permission to read sensitive S3 buckets. The initial misconfiguration opened the door, and the permissive identity design allowed the attacker to exfiltrate over 100 million credit card applications.
High Impact Security Misconfiguration Patterns
The fastest way to improve cyber resilience is to focus on patterns that shorten the path to sensitive data or administrative control. The table below maps common patterns to a concrete check you can run and the standard you should aim for.
| Pattern | Typical Example | Fast Check | Secure Standard |
|---|---|---|---|
| Public management surfaces | Admin panels reachable from the internet | Identify endpoints that allow admin actions from nontrusted networks | Restrict admin access to trusted networks plus strong authentication |
| Overly permissive identity | Roles with broad actions or broad resource scope | List roles that grant write or admin across many resources | Least privilege with scoped roles and regular review |
| Public data exposure | Storage buckets, shares, backup locations accessible publicly | Search for objects readable without authentication | Private by default with explicit sharing and auditing |
| Weak observability | Audit logging disabled or not delivered | Confirm audit logs are enabled and arriving in monitoring | Baseline telemetry with alerts for privileged and anomalous actions |
| Drift from templates | Secure baseline exists but exceptions accumulate | Compare live configuration against the baseline | Continuous drift detection and enforcement |
| Insecure defaults | Default accounts, sample apps, permissive settings | Inventory defaults and confirm they are removed or hardened | Hardened templates used at deployment |
Not every deviation is urgent. An internal service without sensitive access might tolerate a looser setting during development. The dangerous cases are reachable from outside, or they control access to high value assets, or they can escalate privileges.
A Simple Way to Prioritize Fixes
Prioritization works best when it is consistent. A simple scoring model keeps teams aligned and reduces argument-driven triage.

| Dimension | Score 0 | Score 1 | Score 2 |
|---|---|---|---|
| Reachability | Not reachable from outside | Indirectly reachable through another system | Directly reachable from the internet |
| Privilege | Read only or low privilege | Can modify limited resources | Admin or broad write privileges |
| Blast Radius | Single workload | Multiple workloads in a service | Cross environment or organization wide |
| Observability | High signal logging and alerting | Partial logging or delayed alerting | Logging absent or not monitored |
A practical rule is to treat any item scoring 6 or higher as top priority, especially when reachability and privilege both score 2. This keeps the focus on attack paths rather than raw counts of findings.
Start With a Short Operational Pass
If you need immediate progress, use a targeted sweep that produces a small set of high-quality fixes. Run it weekly until the baseline stabilizes:
- List all internet facing services and isolate any admin interfaces and management ports
- Identify identity roles and tokens that grant broad write or admin permissions
- Verify audit logging is enabled and delivered for critical systems
- Find public data exposure in storage, backups, and file sharing settings
- Review recent configuration changes that altered exposure or privileges
This sequence works because it matches common attacker routes. Exposure, credentials, privileges, visibility, and change.
Detect Misconfigurations at the Speed of Change
Annual audits miss what happens in a single week. Detection should be continuous and tied to change.
Two approaches scale well together. Baselines define what secure configuration looks like, while policy as code makes that baseline enforceable in deployment pipelines and testable in production. When guardrails run before deploy, many misconfigurations never reach users. When drift detection runs after deploy, the team sees exceptions that accumulate through manual edits.
High signal change monitoring is the second pillar. Focus on events that materially change risk. Examples include making a service public, granting a role administrative privileges, disabling audit logging, or creating long-lived access keys. For each such change, you want three answers. Who changed it, when it changed, and whether it was approved.
Prevent Misconfiguration With Defaults That Help Teams
Prevention succeeds when the secure option is easier than the insecure one. That is more effective than training people to remember every platform nuance.
A workable program uses hardened templates, short approval paths for exceptions, and enforcement for a narrow set of high risk changes. It also assigns ownership. A finding without a responsible team becomes background noise.
Exception handling deserves special attention. Exceptions should have a named owner, a clear reason, and an expiry date. The expiry is not bureaucracy. It forces the question of whether the deviation is still needed and prevents permanent drift disguised as a temporary workaround.
Metrics That Track Risk Reduction
Counting findings rarely reflects real risk. A single public management interface can matter more than hundreds of minor deviations. Use metrics that connect directly to attacker effort and defender visibility.
Good metrics include the share of internet facing services that meet hardened access requirements, the share of privileged roles reviewed on a fixed cadence, mean time to remediate high impact drift after detection, audit logging coverage for critical systems and successful delivery into monitoring, and the number of active exceptions past their expiry date.
These indicators stay meaningful because they measure outcomes. They show whether your cybersecurity program is shrinking attack paths and improving detection, rather than merely generating reports.
Key Takeaways on Security Misconfiguration
Security misconfiguration is not a niche technical flaw. It is an operational failure mode that grows with complexity. The most effective response is not to chase every possible setting. Build a baseline, enforce a small set of guardrails that prevent the worst exposures, watch high signal changes, and treat drift as a defect with ownership and timelines.
When teams can deploy safely by default and exceptions expire automatically, misconfiguration stops being an unpredictable fire drill and becomes a manageable part of cyber risk control.
Frequently Asked Questions (FAQ)
A vulnerability is a flaw in code or design that can be exploited. A misconfiguration is an unsafe setting that makes an otherwise normal feature dangerous, such as public exposure, overly broad access, or disabled logging. In practice, misconfigurations are often faster to abuse because they can grant legitimate access paths.
Changes that increase reachability, expand privileges, or reduce visibility tend to create the fastest paths to impact. Making a service public, granting admin rights, creating long lived access keys, and disabling audit logs are high risk even when done for valid reasons. These changes should trigger immediate review and monitoring.
Drift is the gap that grows when live systems gradually deviate from a secure baseline due to manual fixes, temporary exceptions, or inconsistent templates. Drift matters because it slowly reintroduces exposure and makes your security posture unpredictable. Treat drift as an operational defect and measure time to bring systems back to baseline.
Use hardened templates and self service defaults so teams inherit secure settings automatically. Enforce a small set of guardrails for the highest risk actions, such as public exposure and broad privilege grants, and make exceptions explicit and time limited. This approach reduces manual review and avoids turning security into a bottleneck.
Public exposure can be intentional when the service is meant for external users. It becomes a misconfiguration when administrative functions are exposed, authentication is weak, or access controls are broader than needed. The safe approach is to separate public application surfaces from management surfaces and apply stronger controls to anything that administers systems or data.
Look for roles that are broad across projects or environments, permissions that include write or admin without a narrow scope, and credentials that live too long. A frequent operational smell is a role that exists because it is convenient rather than because it matches a specific job function. Least privilege is easier to maintain when roles are small, purpose built, and reviewed routinely.
Leave a Reply