
A configuration management database, or CMDB, is a structured system of record for configuration items and the relationships that explain how services are built and operated. The practical value is not the list of assets. It is the ability to answer operational questions quickly and consistently, especially when systems change under pressure.
A CMDB is often mistaken for a procurement catalog, a hardware inventory, or a backup spreadsheet for what teams think they run. Those uses lead to drift because they treat the environment as static. A CMDB is designed for operational truth, the current state that matters for running services, assessing exposure, and making controlled change. In ITIL 4 terms, configuration management exists to provide reliable information about service configuration to support other practices, not to become the place where every possible attribute lives.
In cyber contexts, the biggest misconception is that a CMDB is a security tool on its own. It is not a scanner, not a detection platform, and not a substitute for asset discovery. It becomes security-relevant when it links technical components to business services, owners, and dependencies in ways that make response and risk decisions faster and less guesswork-driven.
Where CMDBs Fit in Cybersecurity Operations
Cybersecurity teams regularly need two things they do not always have: scope and accountability. When an alert fires, responders must quickly determine what is affected, what the system does, and who can change it safely.
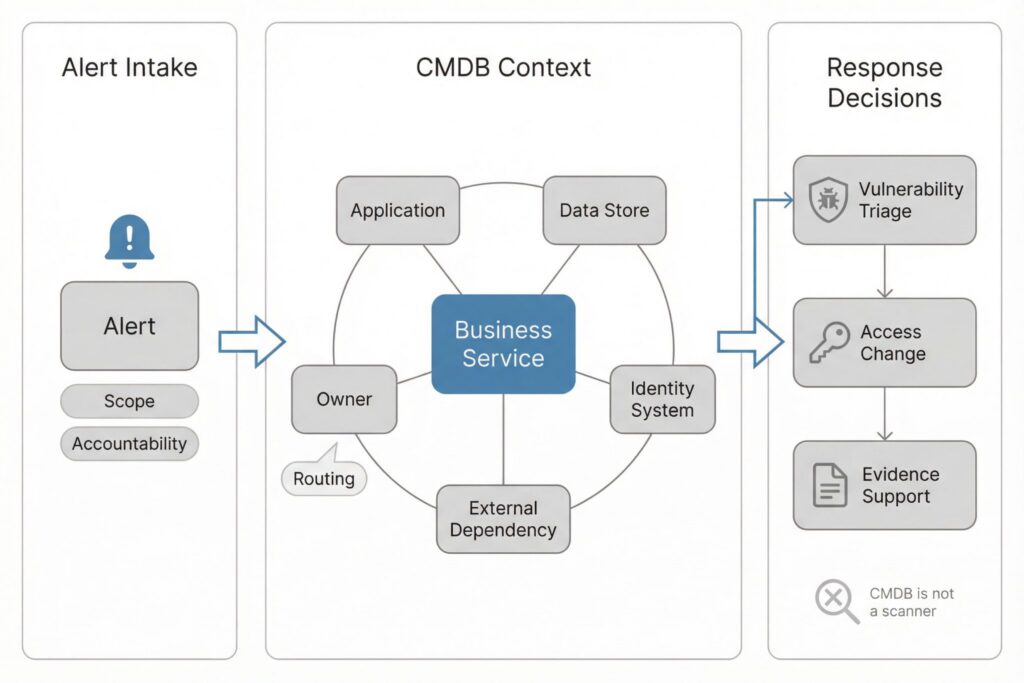
A CMDB supports that workflow by tying a service to its supporting applications, data stores, identity systems, and external dependencies, then tying each of those to an accountable owner.
Consider a realistic incident pattern without relying on a made-up case study. A vulnerability team receives a high-severity advisory for a library that could be present in multiple services. A scanner can report affected hosts or containers, but it often cannot explain whether those hosts sit behind a customer-facing entry point, whether they handle regulated data, or whether they are part of a tier-one business process. A CMDB fills that gap when it maps the workload to the application, the application to the business service, and the service to a criticality label that the organization actually uses for prioritization. The result is a tighter triage loop and fewer broad, disruptive actions.
The same applies to identity and access events. When you discover an overly permissive role, a stale admin group, or a misconfigured SSO integration, the hard part is rarely identifying that it exists. The hard part is determining what depends on it and what breaks if you tighten the control. A CMDB that models identity systems and their consumers helps teams change access policy with fewer surprises, which directly reduces cyber risk.
Frameworks such as NIST SP 800-53 and ISO/IEC 27001 expect organizations to maintain controlled configurations and manage change. A CMDB does not prove compliance by itself, but it can make evidence gathering less manual by keeping ownership, lifecycle state, and linkage to authoritative sources visible and reviewable.
What Belongs in a CMDB
A CMDB should model what you need to operate services and manage risk. The fastest way to undermine it is to attempt an enterprise encyclopedia. Start by choosing configuration item classes that are decision-relevant, then define the minimum attributes that allow people to route work, assess impact, and verify state.
Ownership is not a nice-to-have attribute. In day-to-day operations, unowned configuration items create stalled incidents and risky changes. Ownership needs to be explicit and actionable, meaning a named team or role that can approve change and respond during incidents. When ownership is unclear, the CMDB record may still exist, but it should be treated as incomplete for operational workflows.
Relationships are the backbone.
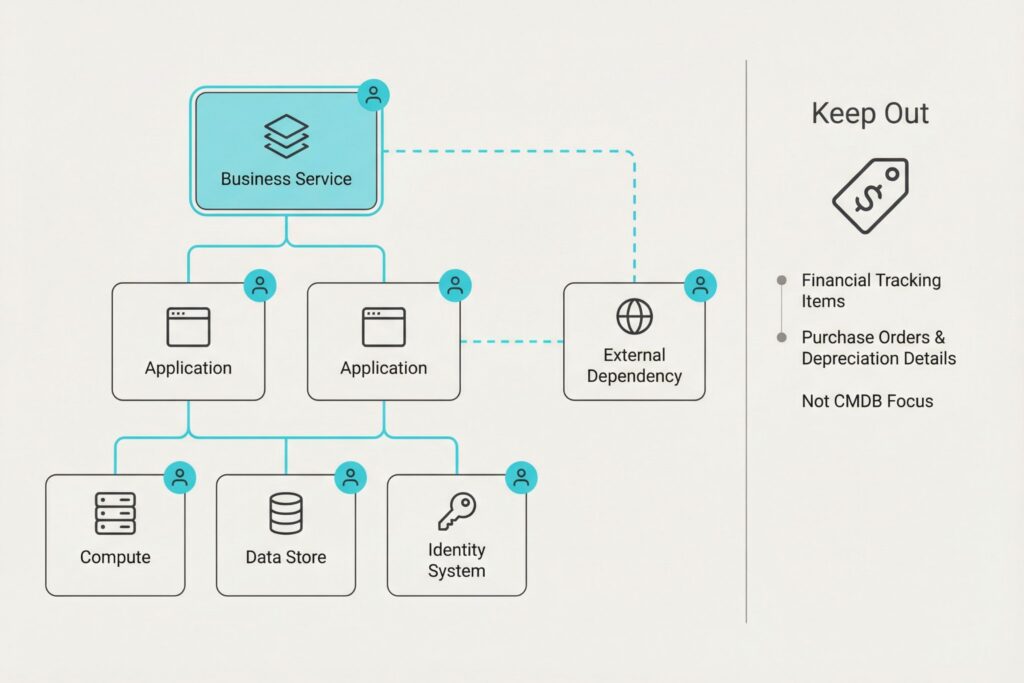
Without dependency mapping, a CMDB becomes a directory. Good relationship modeling usually begins with services and applications, then extends downward into the compute, data, and identity layers that actually influence availability and security posture. External dependencies matter as well. DNS providers, payment gateways, managed authentication services, and certificate authorities can be critical single points of failure or exposure.
Table: Practical CMDB Content That Supports Cyber and Ops
| CI Category | Examples | Minimum Useful Attributes | Relationship Examples That Matter |
|---|---|---|---|
| Business service | Checkout, identity, internal messaging | Criticality, primary owner, support hours, data sensitivity label | Depends on applications, relies on external providers |
| Application | API, batch job, web frontend | Runtime environment, deployment pipeline link, support team, repo reference | Runs on compute, uses data stores, integrates with IAM |
| Compute and platform | VM, Kubernetes cluster, cloud account | Account or location, lifecycle state, platform owner | Hosts applications, exposes ingress points |
| Data store | Database, object storage, message queue | Engine type, backup and encryption status, data owner | Used by applications, feeds analytics, replicates to other stores |
| Identity system | IdP tenant, directory, MFA service | Tenant ID, admin group, policy baseline pointer | Grants access to services, trusted by applications |
| External dependency | DNS, SaaS, CDN, payment provider | Provider name, support tier, status page reference | Supports services, impacts availability and incident response |
Avoid using the CMDB as the primary place to track financial asset attributes such as depreciation or warranty. Those belong in IT asset management. Keep the CMDB focused on what changes, what depends on it, and who must act when something goes wrong.
How CMDB Data Stays Trustworthy
CMDBs fail when they rely on human memory and manual updates for high-volume infrastructure. Trustworthy CMDB data is assembled from authoritative sources, reconciled consistently, and governed with clear responsibilities.
Authoritative sources are context-dependent. Cloud control planes are usually the best source for cloud inventory and resource identifiers. Endpoint management and directory services are authoritative for certain device and identity facts. Cluster APIs provide the most accurate view of orchestrated workloads. A CMDB should ingest from these systems rather than asking people to retype what already exists elsewhere. Manual entry can be appropriate for a small number of high-value relationships, especially service models that require business context, but it should be the exception.
Reconciliation deserves explicit design. In real environments, the same configuration item appears in multiple feeds with mismatched names, tags, or lifecycle indicators. Reconciliation rules decide which source wins for a given attribute, how conflicts are flagged, and how duplicates are merged. If reconciliation is informal, teams stop trusting the CMDB because two screens disagree and nobody knows which one to believe.
Governance should be light enough to operate. A CMDB becomes brittle when every schema change requires committee approval, yet it becomes chaotic when anybody can create classes, attributes, and relationships without review. A practical model assigns a product owner for the CMDB platform, data owners for major CI classes, and stewards who handle relationship modeling standards. The governance mechanism that matters most is enforcement in workflows. Change enablement is a common leverage point. If a production change touches a CI with unknown ownership or missing dependencies, that is a risk signal and the change should proceed only with compensating controls, such as narrower rollout, stronger rollback, or a prerequisite fix to the record.
Implementation Paths and Failure Signals
A CMDB improvement effort goes sideways when it promises full fidelity and universal coverage. Start with a narrow scope anchored to a small set of high-impact services and a few workflows, then expand only when data quality is demonstrably stable.
One reliable path is service-first modeling. Pick a tier-one service, define its owner and support model, map the few dependencies that drive incident triage and change risk, then connect those dependencies to authoritative data feeds. This produces value quickly because responders can use the service map during outages, and security teams can use it during vulnerability prioritization.
Failure signals are usually visible in operations before they are visible in dashboards. On-call engineers stop checking the CMDB because it wastes time. Vulnerability teams maintain separate spreadsheets to identify what matters. Change reviewers cannot estimate impact because dependencies are blank or wrong. Another common sign is uncontrolled growth in low-value attributes. When teams pile on fields that are rarely used, data entry becomes a chore and accuracy drops across the board.
Detection can be simple and honest. Sample a small set of critical services and verify that the service model matches reality. Compare discovered production resources against CMDB records to find unmanaged items. Track conflict queues created by reconciliation rules. A CMDB that is improving will show fewer unresolved conflicts and fewer urgent decisions made without ownership clarity.
Measuring Whether the CMDB Earns Its Keep
Record counts are a vanity metric. A CMDB should be measured by whether it reduces operational friction and cyber risk in repeatable ways.
Use an operational metrics framework that focuses on data quality and workflow outcomes.
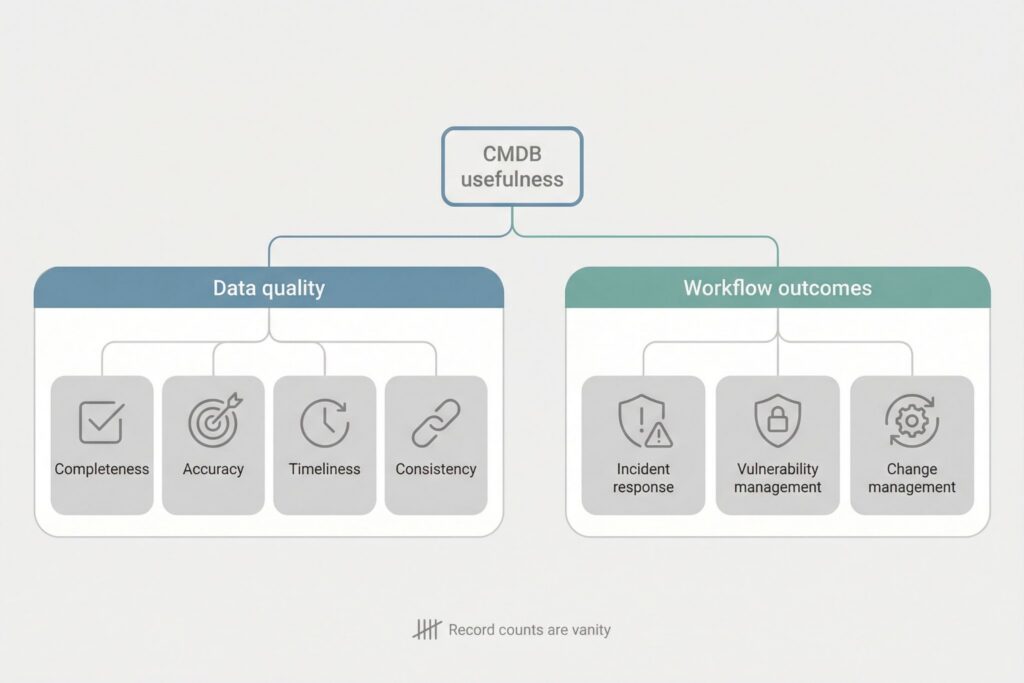
Data quality can be assessed through completeness, accuracy, timeliness, and consistency. Completeness asks whether required fields and relationships exist for in-scope configuration items. Accuracy asks whether those fields match authoritative sources and reality. Timeliness asks whether changes propagate fast enough to support incident response and change control. Consistency asks whether similar items are modeled the same way across teams and environments.
Workflow outcomes should tie back to how people actually work. In incident response, measure whether assignments align with CMDB ownership and whether responders can identify upstream and downstream dependencies without manual detective work. In vulnerability management, measure whether the CMDB enables prioritization by service criticality and exposure rather than by raw asset lists. In change management, measure whether predicted impact from relationships aligns with observed impact during major changes, then use mismatches to improve modeling rather than to blame teams.
A CMDB that earns trust is one that people consult under time pressure. That usage pattern is a stronger signal than any claim about maturity.
CMDB Data Quality Checklist
| Area | Criteria | How to Verify in Practice |
|---|---|---|
| Scope control | In-scope CI classes are explicitly defined and tied to specific workflows | Review CMDB schema and operational runbooks, confirm each class supports incident, change, vuln, or audit evidence needs |
| Ownership | Every production CI has an accountable owning team or role | Sample production CIs across key classes, verify owner field is populated with a real escalation path |
| Service mapping | Tier-one services have a service model with key dependencies | Pick a critical service, validate that apps, data stores, IAM, and external dependencies are linked and usable during a tabletop |
| Authoritative sources | Each major attribute has a designated source of truth | For a CI class, document attribute-to-source mapping, then spot-check that the CMDB value matches the source system |
| Reconciliation rules | Conflicts and duplicates are handled by defined rules, not ad hoc edits | Inspect reconciliation configuration, review conflict queue samples, confirm there is a resolution owner and process |
| Lifecycle state | CI lifecycle states are used and enforced | Verify state transitions exist for planned, active, and retired, then check that retired items are not treated as change targets |
| Relationship integrity | High-value relationships are directional and consistently typed | Validate relationship types and directionality for a sample of services, confirm no ambiguous or free-text dependency fields |
| Timeliness | Updates from authoritative sources arrive fast enough for ops and cyber workflows | Trace a change in a source system through to CMDB update, confirm the CMDB reflects it within the window your teams need |
| Data drift detection | Unmanaged production resources are detectable | Compare discovery feeds or cloud inventory against CMDB records, review exceptions and how they are triaged |
| Workflow enforcement | CMDB quality gates exist in change or release processes | Check change templates or pipelines for validation steps, confirm missing ownership or dependencies triggers review or mitigation |
| Access control | CMDB edit permissions match responsibilities | Review roles and permissions, confirm bulk edits and schema changes are restricted and logged |
| Operational usability | Responders can use the CMDB during incidents without specialist help | Run an incident simulation, confirm on-call can identify owner, dependencies, and relevant evidence links quickly |
Frequently Asked Questions (FAQ)
No. ITAM focuses on financial and contractual lifecycle details, while a CMDB focuses on operational truth, ownership, and dependencies needed for change, incident work, and cyber risk decisions.
Treat something as a CI when changing it can affect a service and you need a reliable owner, lifecycle state, and relationships to make safe decisions. If nobody will act on it during incidents, changes, or vulnerability response, it usually does not belong as a first-class CI.
Start with service-to-application, application-to-data store, application-to-identity system, and service-to-external dependency mappings. In cyber workflows, also prioritize relationships that explain exposure paths, such as internet-facing entry points to the workloads and the identity systems that grant administrative access.
When responders stop using it under pressure because it is slower than tribal knowledge, it is already stale in practice. Another signal is frequent mismatch between discovery sources and CMDB records, especially missing owners, missing dependencies, or retired items still shown as active.
Yes, if you need stable ownership, service context, and reconciled relationships that discovery alone does not provide. Discovery is essential for finding what exists, but a CMDB is where teams agree on what it supports, who is accountable, and how components depend on each other across tools.
Leave a Reply