
Cyber Resilience is the ability to keep critical work moving during a cyber incident and to restore trustworthy operations quickly afterward. It accepts a reality that every security team eventually meets. Prevention reduces risk, but it cannot guarantee uninterrupted business.
A resilient organization knows which services matter most, which dependencies keep them alive, and which decisions must happen fast when something breaks. It can isolate damage without shutting down the entire company, recover without reintroducing the attacker, and improve systems so the next incident is smaller and less expensive.
Cyber Resilience is not a slogan or a slide deck. It is verified execution under pressure, supported by evidence, rehearsal, and clear ownership.
Cyber Resilience And Cybersecurity
Cybersecurity aims to prevent compromise and detect it early. It is built on controls such as hardening, patching, monitoring, identity protection, and secure configuration. Those controls are essential, yet they are not the finish line.
Cyber Resilience includes cybersecurity and then extends the work into continuity, recovery, and adaptation.
The difference becomes obvious in real incidents. When a phishing campaign succeeds or a third party is compromised, teams must decide whether to disable integrations, revoke credentials, isolate networks, stop deployments, or temporarily degrade a service. Organizations that only measure cybersecurity activity often freeze at that moment, not because they lack tools, but because they lack practiced authority, clean recovery paths, and up to date service context.
Resilience is measured by outcomes. Critical services remain available in an acceptable mode. Data integrity stays intact. Decision making remains disciplined even when information is incomplete and time is short.
Four Building Blocks Of Cyber Resilience
Most programs fail when resilience becomes a long checklist owned by no one.
A more useful model focuses on four parts that consistently determine whether the business can continue.
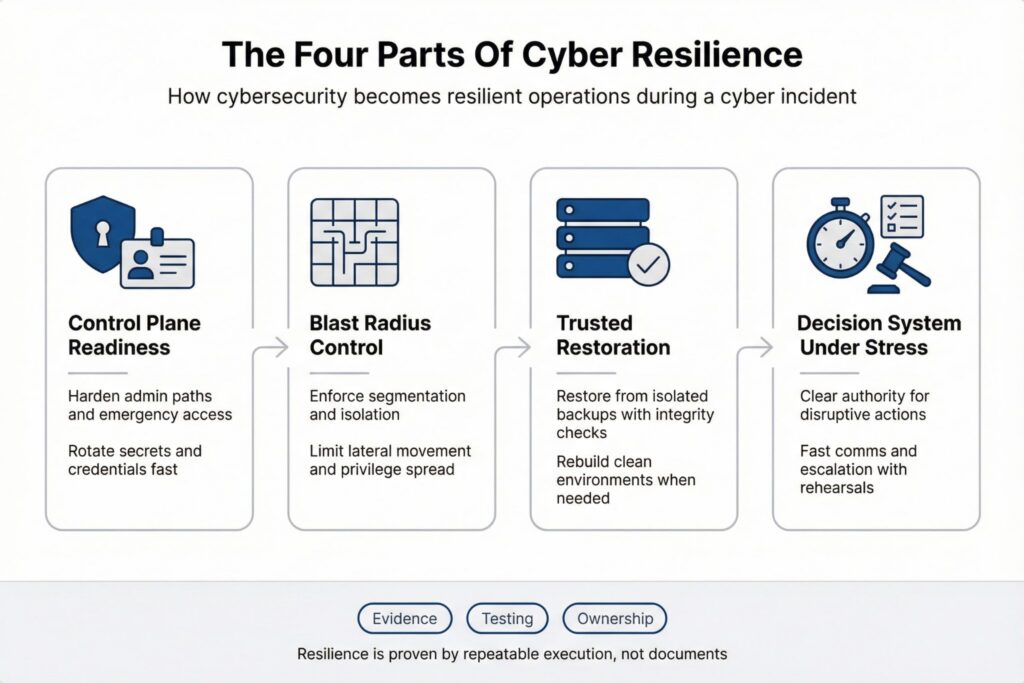
Control plane readiness. If your identity provider, cloud management layer, endpoint management, secrets vault, or CI CD pipeline is compromised or unavailable, recovery of everything else slows dramatically. Control plane resilience includes hardened admin paths, protected emergency access, and the ability to rotate secrets and credentials at speed without guessing what will break.
Blast radius control. Segmentation, tenant isolation, and separate administrative paths limit how far an attacker can move. This is where good architecture saves time and money. If lateral movement is easy, every minute of delay multiplies the problem.
Recoverability you can trust. Backups exist in most organizations. The question is whether they are isolated, restorable, and clean. Restore testing is the only proof that matters. Mature teams also plan for clean environment recovery so restored systems are not placed back into a still compromised network.
Decision system under stress. Incident authority, communications, legal triggers, and escalation paths decide speed. Teams need permission to act quickly and the ability to coordinate without chaos. When decision rights are unclear, the organization hesitates, and attackers benefit from that hesitation.
These parts are cross functional by design. Cyber Resilience improves fastest when security, engineering, operations, and leadership agree on the few decisions that must be fast and the evidence that proves readiness.
Start With Critical Services
Start with services, not platforms. Choose a small number of business critical services and define what acceptable operation means during disruption.
For one service, degraded mode might mean reduced functionality while orders still flow. For another, any downtime might be unacceptable because it affects safety, regulatory deadlines, or customer trust.
Translate that into recovery targets. Recovery time objective sets how quickly the service must return to acceptable operation. Recovery point objective sets the maximum acceptable data loss. Targets should be tiered by business criticality. When every system is treated as top tier, none of them are.
A practical service worksheet captures business owner, technical owner, dependencies, and external integrations. It also captures where trust must hold. Some services can tolerate limited feature loss but cannot tolerate corrupted data. Others can tolerate stale data but cannot tolerate identity compromise.
What Proves Cyber Resilience Works
Evidence keeps the program honest. If a claim cannot be tested, it does not belong in the plan.
| Capability | What Good Looks Like In Production | What To Validate Regularly | Typical Failure Pattern |
|---|---|---|---|
| Service criticality mapping | Critical services have owners and dependency maps that match reality | Review tiers and dependencies against current production | Maps drift and ownership is unclear |
| Identity containment | Compromised accounts do not unlock broad control planes | Privilege paths, token lifetimes, emergency revocation drills | Excess privilege makes containment too disruptive |
| Isolation and segmentation | Lateral movement is hard and auditable | Boundary enforcement tests, admin path separation | Diagram exists but boundaries are not enforced |
| Backup integrity and access | Backups are isolated and cannot be destroyed with routine prod rights | Restore tests with integrity checks and restricted deletion rights | Backups exist but restores fail or are untrusted |
| Clean recovery environment | Restoration happens without reusing compromised systems | Validation of rebuild steps and access controls for recovery tooling | Teams restore into the same compromised network |
| Incident operating model | Decision rights and communications work at speed | Tabletop plus technical exercise with timed decisions | Plans exist but nobody rehearsed authority |
| Post incident change | Lessons learned become production changes | Verify remediation in production and reduce repeat causes | Actions stay in documents and repeat incidents follow |
A Two Week Plan You Can Validate
If you need momentum quickly, focus on what makes incidents spiral.
Begin with one critical service and its control plane dependencies, then prove you can contain identity abuse and restore the service cleanly.
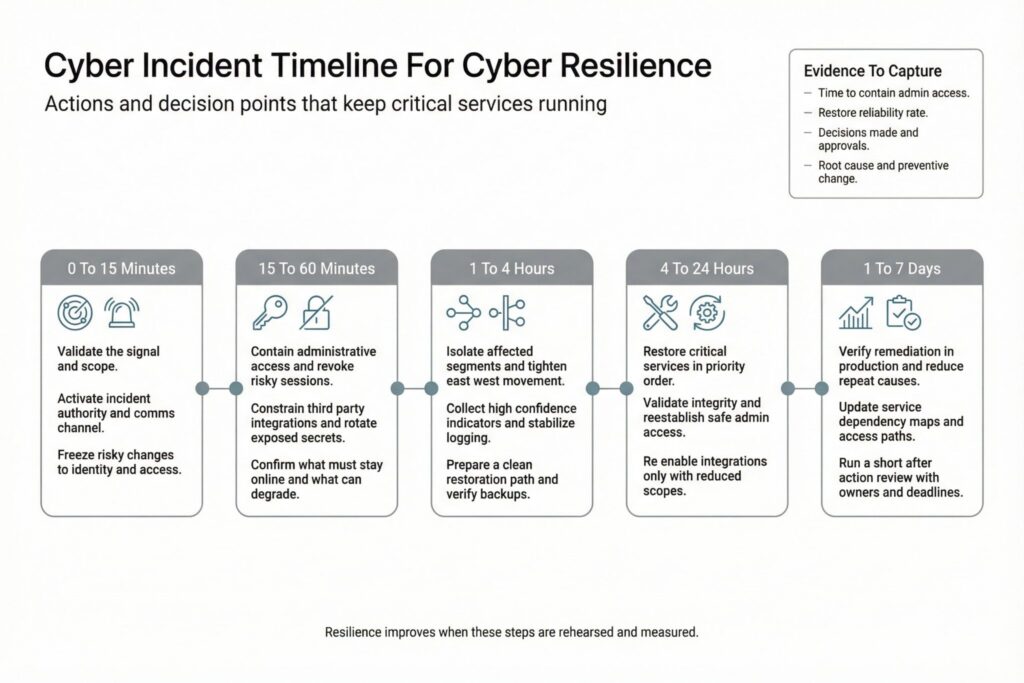
Use the following steps:
- Identify the service owner and incident decision maker. Confirm who can disable integrations, revoke sessions, and approve disruptive containment.
- Map dependencies that must function during recovery. Include identity, DNS, key management, logging, and third party integrations.
- Review privileged access paths. Separate routine admin access from emergency access and ensure rapid credential rotation is feasible.
- Run one restore test that meets the service recovery objectives. Record time, blockers, and integrity checks.
- Hold a timed exercise that includes at least one disruptive decision, then convert outcomes into production changes with owners and deadlines.
This plan stays small on purpose. It produces verified learning in production reality, not generic maturity claims.
Metrics That Show Real Readiness
Resilience metrics should be hard to fake and easy to interpret.
They should measure speed, reliability, and repeatability rather than tool activity.
| Metric | What It Measures | How To Define Start And Stop | Why It Matters |
|---|---|---|---|
| Time to contain administrative access | Speed of stopping risky admin sessions and tokens | Start at first high confidence signal, stop when sessions are revoked and privileged paths are controlled | Admin access drives rapid blast expansion |
| Restore reliability rate | Whether restores meet objectives consistently | Count scheduled restore tests that meet time and integrity checks | Backup without successful restore is an illusion |
| End to end recovery time for a critical service | Real recovery including dependencies | Start when recovery begins, stop when service is operating acceptably with required dependencies | Partial recovery often hides downstream failure |
| Repeat cause rate | Whether the same gap causes new incidents | Track incidents tied to previously identified causes | Repeat incidents indicate failed learning |
| Time to restrict third party exposure | Speed of reducing integration risk | Start at vendor risk signal, stop when scopes, secrets, or connectivity are restricted | Third party paths can bypass strong perimeter controls |
Avoid metrics that reward motion without readiness. Alert volume, patch counts, and closed tickets can support operations, but they do not prove Cyber Resilience.
Where Cyber Resilience Breaks Down
The most common failure is confusing backup presence with recovery readiness. Restores fail because permissions are missing, data is corrupt, or the recovery environment is not clean. In ransomware scenarios, backups can also be targeted when they share deletion rights with production.
Identity sprawl is another predictable weakness. Long lived tokens, shared accounts, broad admin scopes, and inconsistent multi factor enforcement make containment slow and disruptive. Teams hesitate because they fear breaking business operations, and attackers benefit from the delay.
Hidden dependencies amplify damage. A service can be restored yet remain unusable because identity, DNS, or a third party integration is unavailable. Dependency testing closes that gap, and it also prevents emergency changes from causing new outages during an incident.
One additional trap is crisis communication drift. If internal status updates, customer messaging, and executive briefings are not coordinated, the organization loses time, trust, and decision clarity at the exact moment it needs the opposite.
What Changes In SaaS And Regulated Teams
SaaS and multi tenant systems should prioritize tenant isolation and safe defaults in admin tooling. Scoped tokens, segmented data paths, and strong rate limits can prevent one compromised account from affecting many customers.
Enterprises with complex identity and network estates should treat control plane resilience as a first class reliability requirement. If identity, secrets, or cloud management are fragile, every cyber incident becomes slower and more expensive.
Regulated sectors should align resilience work with formal expectations, including incident testing, third party oversight, and documented recovery objectives. In the EU financial sector, DORA makes digital operational resilience a governance responsibility, which increases the value of evidence driven testing and clear decision rights.
The Standard For Cyber Resilience In Practice
An organization earns Cyber Resilience when it can answer simple questions with evidence and not with optimism.
Which services must remain available. Who can isolate damage. How quickly compromised access can be revoked without guessing. Whether clean restoration is possible on demand. What changed in production after the last incident.
Cyber Resilience is not a separate program competing with cybersecurity. It is cybersecurity that still works when conditions are messy, people are tired, and the attacker has already landed.
Frequently Asked Questions(FAQ)
No. Smaller teams often benefit more because a single outage or breach can consume all capacity for weeks.
Pick one critical dataset, restore it into an isolated environment, and validate both application function and data integrity. If the restore requires special people, undocumented steps, or production credentials, treat it as a failed test.
Start from business impact, not technology preferences. Define the maximum tolerable downtime and data loss per critical service, then pressure test those numbers against dependency reality and staffing.
Revoking or constraining privileged access. Attackers expand fastest through administrative sessions, tokens, and broad scopes.
Constrain the integration first by disabling it or reducing scopes, then rotate related secrets and review access paths. Treat re-enabling as a controlled change with evidence, not a return to normal.
Teams stop at discussion. If the exercise does not produce production changes with owners and deadlines, it trains confidence rather than capability.
Leave a Reply